搜索到
64
篇与
的结果
-
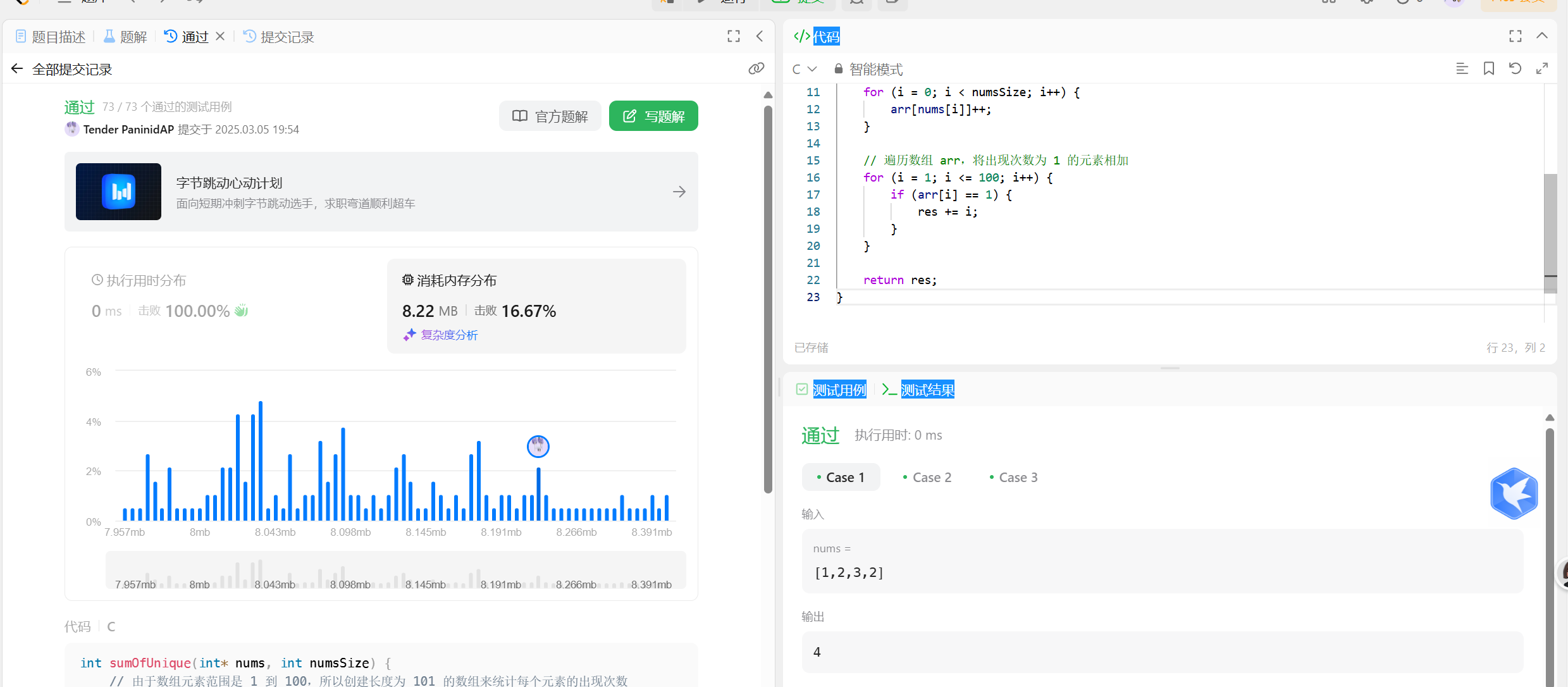
 力扣1748唯一元素的和 还是比较简单的 直接哈希丝滑小连招上题目代码测试用例测试用例测试结果唯一元素的和已解答简单相关标签相关企业提示给你一个整数数组 nums 。数组中唯一元素是那些只出现 恰好一次 的元素。请你返回 nums 中唯一元素的 和 。示例 1:输入:nums = [1,2,3,2]输出:4解释:唯一元素为 [1,3] ,和为 4 。示例 2:输入:nums = [1,1,1,1,1]输出:0解释:没有唯一元素,和为 0 。示例 3 :输入:nums = [1,2,3,4,5]输出:15解释:唯一元素为 [1,2,3,4,5] ,和为 15 。提示:1 <= nums.length <= 1001 <= nums[i] <= 100那么代码也很简单int sumOfUnique(int* nums, int numsSize) { int arr[102]; int res = 0; int i =0; memset(arr,0,sizeof(int) * 102); for(i;i<102;i++){ arr[nums[i]]++; } for(i = 0;i<102;i++){ if(arr[i] == 1){ res += 1; } } return res; }直接上结果
力扣1748唯一元素的和 还是比较简单的 直接哈希丝滑小连招上题目代码测试用例测试用例测试结果唯一元素的和已解答简单相关标签相关企业提示给你一个整数数组 nums 。数组中唯一元素是那些只出现 恰好一次 的元素。请你返回 nums 中唯一元素的 和 。示例 1:输入:nums = [1,2,3,2]输出:4解释:唯一元素为 [1,3] ,和为 4 。示例 2:输入:nums = [1,1,1,1,1]输出:0解释:没有唯一元素,和为 0 。示例 3 :输入:nums = [1,2,3,4,5]输出:15解释:唯一元素为 [1,2,3,4,5] ,和为 15 。提示:1 <= nums.length <= 1001 <= nums[i] <= 100那么代码也很简单int sumOfUnique(int* nums, int numsSize) { int arr[102]; int res = 0; int i =0; memset(arr,0,sizeof(int) * 102); for(i;i<102;i++){ arr[nums[i]]++; } for(i = 0;i<102;i++){ if(arr[i] == 1){ res += 1; } } return res; }直接上结果 -
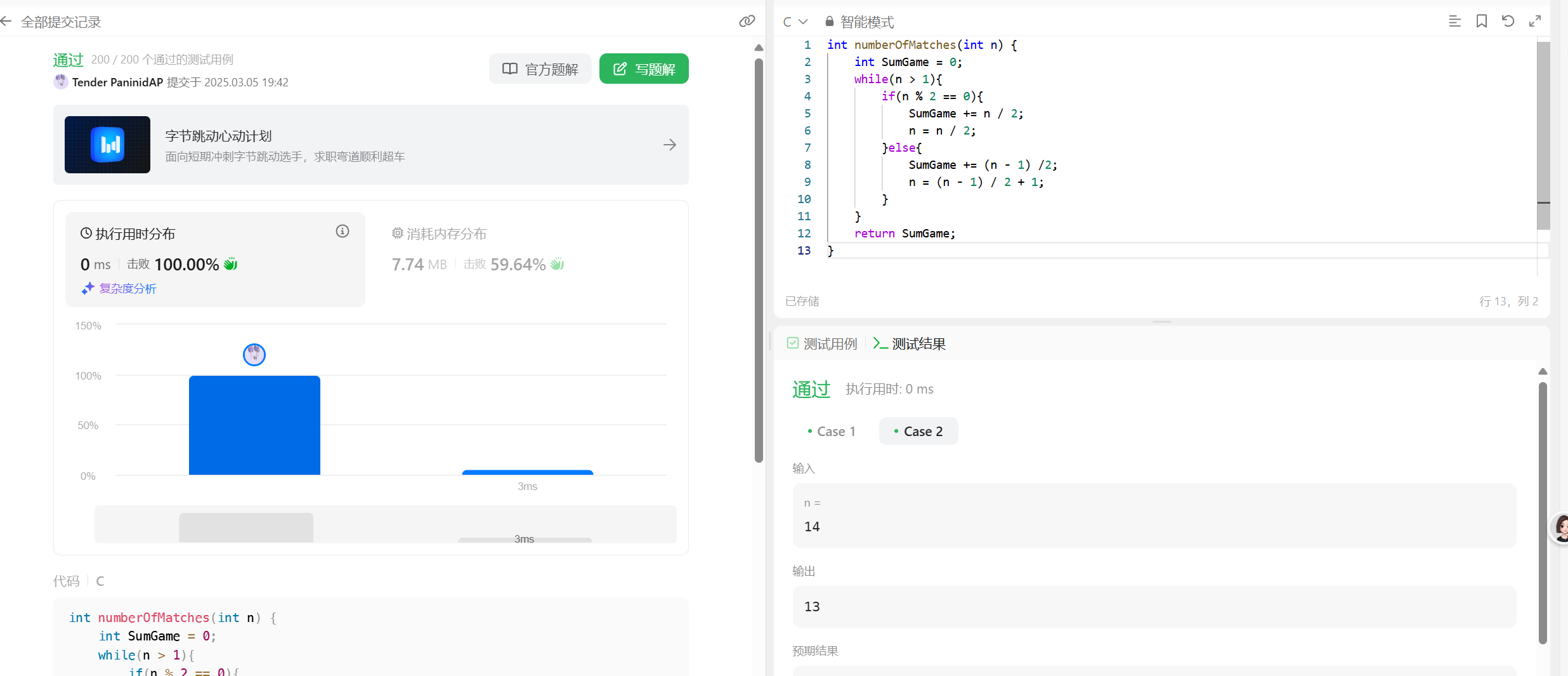
力扣1688比赛中的配对次数 太简单了,直接上题目和代码给你一个整数 n ,表示比赛中的队伍数。比赛遵循一种独特的赛制:如果当前队伍数是 偶数 ,那么每支队伍都会与另一支队伍配对。总共进行 n / 2 场比赛,且产生 n / 2 支队伍进入下一轮。如果当前队伍数为 奇数 ,那么将会随机轮空并晋级一支队伍,其余的队伍配对。总共进行 (n - 1) / 2 场比赛,且产生 (n - 1) / 2 + 1 支队伍进入下一轮。返回在比赛中进行的配对次数,直到决出获胜队伍为止。示例 1:输入:n = 7输出:6解释:比赛详情:第 1 轮:队伍数 = 7 ,配对次数 = 3 ,4 支队伍晋级。第 2 轮:队伍数 = 4 ,配对次数 = 2 ,2 支队伍晋级。第 3 轮:队伍数 = 2 ,配对次数 = 1 ,决出 1 支获胜队伍。总配对次数 = 3 + 2 + 1 = 6示例 2:输入:n = 14输出:13解释:比赛详情:第 1 轮:队伍数 = 14 ,配对次数 = 7 ,7 支队伍晋级。第 2 轮:队伍数 = 7 ,配对次数 = 3 ,4 支队伍晋级。第 3 轮:队伍数 = 4 ,配对次数 = 2 ,2 支队伍晋级。第 4 轮:队伍数 = 2 ,配对次数 = 1 ,决出 1 支获胜队伍。总配对次数 = 7 + 3 + 2 + 1 = 13提示:1 <= n <= 200直接上代码int numberOfMatches(int n) { int SumGame = 0; while(n > 1){ if(n % 2 == 0){ SumGame += n / 2; n = n / 2; }else{ SumGame += (n - 1) /2; n = (n - 1) / 2 + 1; } } return SumGame; }简直无脑
-
大模型中的 Token:AI 语言魔法的关键解码器 在自然语言处理(NLP)的大模型中,Token 是一个核心概念。理解 Token 对于解读模型的工作原理、训练机制以及生成内容的方式至关重要。本文将从基础入手,逐步深入地介绍 Token 的定义、作用、以及在大模型中的具体应用。什么是 Token?基本定义Token 是对文本进行分解后形成的最小单位。它可以是:单个字符:如a,b。一个词:如hello,world。一个子词:如un-(前缀),-ing(后缀)。标点符号:如,,.。特殊符号:如(结束符),(未知词)。Token 与字和词的关系Token 不等同于字或词,而是一种介于两者之间的处理方式。例如:在英文中,running可能被分解为run和ing。在中文中,自然语言处理通常会按词分解为自然、语言和处理,也可能直接用字符作为 Token。为什么需要 Token?语言是连续的,而模型需要离散的输入。Token 的引入是为了将语言映射到可以被机器理解的离散数据形式,方便处理和学习。Token 在大模型中的作用输入编码在处理自然语言时,原始文本首先被分解成一系列 Token,然后被编码为数字 ID(通常是整数),以便输入模型。例如:原始文本:I love AI.Token 化:("I","love","AI",".")编码:(101,1567,7896,102)训练与预测大模型通过学习 Token 的分布规律,预测下一个 Token 或生成新的句子。以下是两个典型应用:语言建模:根据前面的 Token 序列,预测下一个 Token。生成任务:根据输入的 Token 序列,生成满足任务要求的输出文本。控制序列长度Token 的数量直接影响模型的性能和计算开销。例如,GPT 模型有最大 Token 限制(如 4096 tokens),这决定了它能处理的上下文长度。Token 的分解方式:分词算法详解为了将文本分解为 Token,需要使用特定的分词算法。以下是几种常见方法:基于规则的分词最简单的方式,按空格或标点直接拆分。例如:输入:I love programming.输出:("I","love","programming",".")Byte-Pair Encoding(BPE)BPE 是一种基于统计的子词分词方法,广泛用于 GPT 系列模型:将文本初始化为单字符序列。找到出现频率最高的字符对,合并为新 Token。重复步骤,直到达到预定 Token 数量。例子:输入:low,lower,lowest初始 Token:("l","o","w","l","o","w","e","r","l","o","w","e","s","t")经过多轮合并后:("low","lower","lowest")SentencePieceSentencePiece 是一种模型无关的分词器,可以直接处理未分词的文本。它使用 BPE 或 Unigram 算法进行分词,适用于多种语言。WordPiece与 BPE 类似,但主要用于 BERT 模型。它会优先生成常见词作为 Token,同时允许不常见词分解为更小的子词。Token 在大模型中的结构与优化Embedding 表每个 Token 都对应一个向量表示,存储在模型的嵌入层(Embedding layer)中。嵌入层的作用是将离散的 Token 映射到连续的向量空间。模型层的作用编码器(Encoder):处理输入 Token,生成上下文相关的表示。解码器(Decoder):根据编码器输出和历史 Token,生成下一个 Token。Token 优化为了提升效率和准确性,研究人员会优化 Token 的设计和处理:减少无用 Token:如避免将常见标点符号频繁拆分。增加子词共享:通过共享 Token 表,提升跨任务的泛化能力。上下文压缩:通过合并低频 Token,减少 Token 总数。与 Token 相关的实际问题与挑战长序列问题长文本会生成更多的 Token,导致计算成本增加。这对上下文较长的任务(如总结长文章)是一个挑战。多语言适配不同语言的分词方式差异显著,需要设计统一的 Token 化方法。例如,中文需要按字分解,而阿拉伯语需要考虑词形变化。未知 Token 的处理模型可能遇到未在训练中见过的词。这时会用特殊 Token替代,可能降低生成内容的流畅性。Token 的未来展望随着模型能力的提升,Token 的设计也在不断演进:动态分词根据任务动态调整 Token 化方式,兼顾精度和效率。超长上下文通过压缩 Token 或改进架构,处理更长的输入序列。多模态 Token将文字、图像等统一编码为 Token,支持多模态任务。结语Token 是大模型中最基本却至关重要的组成部分。从文本分解到生成语言,Token 的处理贯穿始终。了解 Token 的原理和应用,不仅有助于深入理解大模型的工作机制,还能为其进一步优化和应用提供理论支持。
-
-
力扣2129 - 讲标题首字母大学 题目:给你一个字符串 title ,它由单个空格连接一个或多个单词组成,每个单词都只包含英文字母。请你按以下规则将每个单词的首字母 大写 :如果单词的长度为 1 或者 2 ,所有字母变成小写。否则,将单词首字母大写,剩余字母变成小写。请你返回 大写后 的 title 。示例 1:输入:title = "capiTalIze tHe titLe"输出:"Capitalize The Title"解释:由于所有单词的长度都至少为 3 ,将每个单词首字母大写,剩余字母变为小写。示例 2:输入:title = "First leTTeR of EACH Word"输出:"First Letter of Each Word"解释:单词 "of" 长度为 2 ,所以它保持完全小写。其他单词长度都至少为 3 ,所以其他单词首字母大写,剩余字母小写。示例 3:输入:title = "i lOve leetcode"输出:"i Love Leetcode"解释:单词 "i" 长度为 1 ,所以它保留小写。其他单词长度都至少为 3 ,所以其他单词首字母大写,剩余字母小写。直接上代码 char* capitalizeTitle(char* title) { int titleLength = strlen(title); int start = 0; for (int i = 0; i <= titleLength; i++) { // 当遇到空格或者字符串结束符时,处理当前单词 if (title[i] == ' ' || title[i] == '\0') { if (i - start <= 2) { // 单词长度小于等于 2,将所有字母转换为小写 for (int j = start; j < i; j++) { title[j] = tolower(title[j]); } } else { // 单词长度大于 2,首字母大写,其余字母小写 title[start] = toupper(title[start]); for (int j = start + 1; j < i; j++) { title[j] = tolower(title[j]); } } // 更新下一个单词的起始位置 start = i + 1; } } return title; }